はじめに
前回の記事
この記事は、ゼロから作るDeep Learning(以下ゼロつく)のアウトプット学習用に書いています。
今回は3章の1〜4までを扱います。
第3章はニューラルネットワークについてです。
同じように機械学習・ディープラーニングを学習している方にもわかりやすいように書きたいと思います。
理解を深めるため、ぜひ書籍と併せて読んでいただければと思います。
パーセプトロンからニューラルネットワークへ
2章でも勉強したように、パーセプトロンには1つ課題がありました。
重みやバイアスを設定する作業を手動でやらなければならない点です。
ニューラルネットワークは、その課題を解決することができます。
適切な重みパラメータをデータから自動で学習することができます。
それではパーセプトロンとニューラルネットワークの違いは何でしょうか。
それは、活性化関数の有無です。ニューラルネットワークでは活性化関数というものが登場します。
これから説明したいと思います。
活性化関数
2章で説明した通り、パーセプトロンの式は次のように表すことができます。
$$
y = \begin{cases}
0 \quad (w_1 x_1 + w_2 x_2 + b \leq 0) \\
1 \quad (w_1 x_1 + w_2 x_2 + b > 0)
\end{cases}
$$
これを次のように書き換えます。
$$
y = h(b + w_1 x_1 + w_2 x_2)
$$
$$
h(x)
= \begin{cases}
0 \quad (x \leq 0) \\
1 \quad (x > 0)
\end{cases}
$$
ここで出てくる\(h(x)\)が活性化関数です。
入力信号の総和が\(h(x)\)によって変換され、\(y\)として出力されます。
活性化関数は入力信号の総和がどのように発火するかを決定する役割があります。
活性化関数
ニューラルネットワークでは次のような活性化関数が用いられます。
- ステップ関数
- シグモイド関数
- ReLU関数
ステップ関数
パーセプトロンで利用している関数がステップ関数です。
閾値を境にして出力が変わります。グラフでみるとわかりやすいですが、階段的に変わるからです。
簡単に実装してみます。
実装
def step_function(x) :
if x >0 :
return 1
else :
return 0これで簡単に実装できましたが、1点問題があります。
\(x\)には実数しか入力することができません。
実際にはNumpy配列に対応させる必要がある場合が多いので、以下のようにします。
def step_function(x) :
return np.array(x > 0, dtype=np.int)Numpy配列に対して、不等号の演算を行った場合、ブーリアン配列が生成されます。
ブーリアン配列は、0より大きい場合にTrue、0以下の場合にFalseを返します。
ステップ関数で欲しい結果は0か1のint型なので、上記のようにする必要があります。
グラフに描画してみると次のようになります。
def step_function(x) :
return np.array(x > 0, dtype=np.int)
x = np.arange(-5.0, 5.0, 0.1)
y = step_function(x)
plt.plot(x, y)
plt.ylim(-0.1, 1.1)
plt.show()
シグモイド関数
シグモイド関数は以下の式で表されます。
$$
h(x)
= \frac{1}{1 + \exp(-x)}
$$
シグモイド関数を通すと出力は必ず0〜1の値になります。
これは確率を表していると言えます。
実装
まずはシグモイド関数の定義です。
def sigmoid(x) :
return 1 / (1 + np.exp(-x))シグモイド関数にNumpy配列を入力すると、演算結果もNumpy配列で出力されます。
x = np.array([-0.1, 1.0, 2.0])
sigmoid(x)
# 出力
array([0.47502081, 0.73105858, 0.88079708])次に、グラフに描画してみます。
\(y\)軸がシグモイド関数です。
import matplotlib.pyplot as plt
x = np.arange(-5.0, 5.0, 0.1)
y = sigmoid(x)
plt.plot(x, y)
plt.ylim(-0.1, 1.1) # y軸の範囲を指定
plt.show()
ステップ関数とシグモイド関数の比較すると、滑らかさが違うことがわかります。
パーセプトロン(ステップ関数)は0か1を出力するのに対し、ニューラルネットワーク(シグモイド関数)は0から1までの間の連続値を出力します。
また、どちらも非線形な関数であることもわかります。
ニューラルネットワークでは、必ず活性化関数に非線形関数を用います。
それは、線形関数を用いた場合、隠れ層のないネットワークを表現することになるからで、多層にすることのメリットを享受できないからです。
ReLU(Rectified Linear Unit)関数
ニューラルネットワークでは昔からシグモイド関数を用いることが多かったようですが、最近ではReLU関数を用いることが多いようです。
なぜReLU関数を使うことが多いのか。これはバックプロパゲーションの勾配消失問題に対処するためだと考えられます。
ReLU関数は、入力が0を超えていれば、その入力の値をそのまま出力し、超えていなければ0を出力する関数です。
数式に表すと以下のようになります。
$$
h(x)
= \begin{cases}
x \quad (x > 0) \\
0 \quad (x \leq 0)
\end{cases}
$$
実装
非常にシンプルなので、コード実装も次のように簡単に表せます。
def relu(x) :
return np.maximum(0, x)np.maximumは入力された値から大きい方を出力する関数です。
また、グラフに描画してみます。
def relu(x) :
return np.maximum(0, x)
x = np.arange(-5, 5, 0.1)
y = relu(x)
plt.plot(x, y)
plt.ylim(-0.1, 1.1)
plt.show()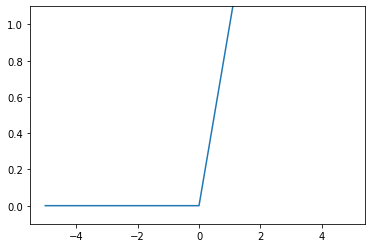
多次元配列の計算
ニューラルネットワークの実装には、多次元配列の計算をNumpyで行う必要があります。
ここで主に使う関数など(Numpy以外も含む)は以下の通りです。
- np.array()
- np.ndim()・・・配列の次元数を取得
- .shape ・・・配列の形状を取得
- np.dot() ・・・ベクトル、行列の式を計算
np.array()についてはこれまでも実装に使っていますが、Numpy配列を生成するのに用います。
それでは、1次元配列と多次元配列の例を見ていきます。
# 1次元配列
A = np.array([1, 2, 3, 4])
print(A)
print(np.ndim(A))
print(A.shape)
print(A.shape[0])
# 出力
[1 2 3 4]
1
(4,)
4次は2次元配列です。2行3列の行列を生成します。
# 2次元配列
B = np.array([[1, 2], [3, 4], [5, 6]])
print(B)
print(np.ndim(B))
print(B.shape)
# 出力
[[1 2]
[3 4]
[5 6]]
2
(3, 2)行列の積(数学)
Numpyのnp.dot()を用いることで行列の積を計算することができます。
行列積の計算なので、2×3と3×2など、対応する次元を一致させる必要があります。
行列積の計算の例を見てみます。
# 2×3行列と3×2行列の積
A = np.array([[1, 2, 3], [4, 5, 6]])
print(A.shape)
B = np.array([[1, 2], [3, 4], [5, 6]])
print(B.shape)
np.dot(A, B)
# 出力
(2, 3)
(3, 2)
array([[22, 28],
[49, 64]])3層ニューラルネットワークの実装
ここではNumpyで3層のニューラルネットワークを実装します。
ニューロンの数は、以下の通りです。
- 入力層(第0層) :2つ
- 隠れ層(第1層) :3つ
- 隠れ層(第2層) :2つ
- 出力層(第3層) :2つ
書籍には図がしっかりと掲載してあるので、併せて読むことをオススメします。
第0層は\(x_1\)…とバイアスである\(b_1\)、
第1層は重み付き和の\(a_1\)…、
そして出力として、第3層で\(y_1\)…と示していきます。
ここまでは、パーセプトロンの章で触れたので概念の理解は大丈夫かと思います。
第1層目の重み付き和は、行列の積を用いると次のように表すことができます。
$$
\mathbf{A}^{(1)}
= \mathbf{X} \mathbf{W}^{(1)} + \mathbf{B}^{(1)}
$$
それぞれにある右上の(1)は、階層を表していて、第1層のため、(1)となっています。
また、
\(\mathbf{A}^{(1)}\)は、\(a_1\)から\(a_3\)までの行列、
\(\mathbf{X}\)は、\(x_1\)から\(x_2\)までの行列と、
それぞれの行列のアルファベットを大文字にしたものです。
ここから、行列の積を使って、第1層から第3層まで実装していきます。(数値は適当な値)
入力層→第1層
X = np.array([1.0, 0.5])
W1 = np.array([[0.1, 0.3, 0.5], [0.2, 0.4, 0.6]])
B1 = np.array([0.1, 0.2, 0.3])
print(W1.shape)
print(X.shape)
print(B1.shape)
A1 = np.dot(X, W1) + B1
# 出力
(2, 3)
(2,)
(3,)これで第1層の実装ができました。
しかし、第2層に渡していく際に、活性化関数を通さなければなりませんでした。
活性化関数で変換されたものは\(z\)と表します。
Z1 = sigmoid(A1) # 以前定義したもの
print(A1)
print(Z1)
# 出力
[0.3 0.7 1.1]
[0.57444252 0.66818777 0.75026011]第1層→第2層
続いて第1層から第2層までの実装を行います。
ここは同様に進めていきます。
W2 = np.array([[0.1, 0.4], [0.2, 0.5], [0.3, 0.6]])
B2 = np.array([0.1, 0.2])
print(Z1.shape)
print(W2.shape)
print(B2.shape)
# 出力
(3,)
(3, 2)
(2,)活性化関数を通します。
A2 = np.dot(Z1, W2) + B2
Z2 = sigmoid(A2)第2層→出力層
出力層の実装では、これまでと活性化関数の部分が異なります。
恒等関数を活性化関数として用います。
恒等関数は、入力をそのまま出力する関数です。
def identity_function(x) : # 恒等関数をわかりやすくするために定義
return x
W3 = np.array([[0.1, 0.3], [0.2, 0.4]])
B3 = np.array([0.1, 0.2])
A3 = np.dot(Z2, W3) + B3
Y = identity_function(A3)3層ニューラルネットワークの実装まとめ
これまでの実装をまとめてみます。
def init_network() :
network = {}
network['W1'] = np.array([[0.1, 0.3, 0.5], [0.2, 0.4, 0.6]])
network['b1'] = np.array([0.1, 0.2, 0.3])
network['W2'] = np.array([[0.1, 0.4], [0.2, 0.5], [0.3, 0.6]])
network['b2'] = np.array([0.1, 0.2])
network['W3'] = np.array([[0.1, 0.3], [0.2, 0.4]])
network['b3'] = np.array([0.1, 0.2])
return network
def forward(network, x) :
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, W3) + b3
y = identity_function(a3)
return y
network = init_network() # 重みとバイアスの初期化
x = np.array([1.0, 0.5])
y = forward(network, x) # 入力を出力へ変換する関数
print(y)
# 出力
[0.31682708 0.69627909]forwardという単語が出てきた通り、入力から出力方向への伝達処理を表しています。
これをニューラルネットワークの順伝播と呼びます。