
はじめに
今回の記事は、前回に引き続き、私が受講しているE資格 JDLA認定プログラムの「ラビットチャレンジ」のレポート記事です。
今回のテーマは深層学習です。
講座ではDay1〜Day4まで分かれており、今回はDay2(前半)に取り組みます。
Day2は主に、畳み込みニューラルネットワーク(CNN)について扱います。
確認テスト、実装演習も併せて載せていきます。
確認テスト(前回の復習)
- 連鎖律の原理を使い、\(\frac{dz}{dx}\)を求めよ。
$$
\frac{dz}{dx}=\frac{dz}{dt}\times\frac{dt}{dx}
$$
$$
\left\{
\begin{array}{l}
\frac{dz}{dt}=2t \\
\frac{dt}{dx}=1
\end{array}
\right.
$$
$$
\frac{dz}{dx}=\frac{dz}{dt}\times\frac{dt}{dx}=2t\times 1=2(x+y)
$$
勾配消失問題
誤差逆伝播法が下位層に進んでいくにつれて、勾配がどんどん緩やかになっていきます。
すると、下位層のパラメータがほとんど変わらなくなるため、全体最適解に収束しなくなります。
このことを、勾配消失問題と呼びます。
グラフ等で可視化することで、勾配消失を起こしているか確認します。
シグモイド関数の場合、微分の最大値は0.25となるため下位層に進むにつれて0.25の2乗、更に2乗となっていくため0に近づいていくことになります。
勾配消失問題の解決方法
活性化関数の選択
ReLU関数(ランプ関数、正規化線形関数)
0~1の範囲の値を出力するシグモイド関数と違い、
ReLU関数は、入力値が閾値(0)を超えている場合、入力値をそのまま出力するため勾配消失が起こりにくいです。
微分した結果が\(x\leq 0\)の時は、\(0\)、\(x>0\)の時は、\(1\)となります。
重みの初期値設定
Xavier
各重みに対して、前の層のノード数(ユニット数)の平方根で除算した値を初期値とするアルゴリズムです。
Xavierで初期値を設定する際に合わせて用いられる活性化関数が、ReLU関数やシグモイド関数、双曲線正接関数(tanh)です。
self.params['W1'] = np.random.randn(input_size, hidden_size) / nq.sqrt(input_layer_size)
self.params['W2'] = np.random.randn(hidden_size, output_size) / nq.sqrt(hidden_layer_size)
He
各重みに対して、前の層のノード数(ユニット数)の平方根で除算した値に\(\sqrt{2}\)を掛けた値を初期値とするアルゴリズムです。
Heで初期値を設定する際に合わせて用いられる活性化関数がReLU関数です。
self.params['W1'] = np.random.randn(input_size, hidden_size) / nq.sqrt(input_layer_size) * np.sqrt(2)
self.params['W2'] = np.random.randn(hidden_size, output_size) / nq.sqrt(hidden_layer_size) * np.sqrt(2)バッチ正規化
バッチ正規化は、ミニバッチ単位で入力値のデータの偏りを抑制する手法です。
活性化関数に値を渡す前後に、バッチ正規化の処理を含む層を加えます。
バッチ正規化項への入力値は、入力値に重みをかけてバイアスを加えた部分、または活性化関数の出力値です。
確認テスト
- シグモイド関数を微分した時、入力値が0の時に最大値を取る。その値として正しいものは何か。
⇨\(f(u)=(1-sigmoid(u))\cdot sigmoid(u)\)より、入力値を0にした場合出力は0.5となります。
代入すると、\(0.5\times0.5=0.25\)となります。
- 重みの初期値に0を設定すると、どのような問題が発生するか。簡潔に説明せよ。
⇨すべての重みの値が均一に更新されることになるため、多数の重みをもつ意味がなくなり、正しい学習が行えない。
- 一般的に考えられるバッチ正規化の効果を2点挙げよ。
⇨計算が高速で、過学習を抑えることができる。
また、中間層の重みの安定度が増し、勾配消失が起こりづらい。
勾配消失問題 実装演習
環境はローカルで、jupyter notebookをVS Codeで動かしました。
まずは、sys.pathの設定をします。
import sys
sys.path.append('./DNN_code_colab_lesson_1_2')必要なライブラリのインポート
import numpy as np
from common import layers
from collections import OrderedDict
from common import functions
from data.mnist import load_mnist
import matplotlib.pyplot as plt勾配消失の実装(シグモイド関数)
# mnistをロード
(x_train, d_train), (x_test, d_test) = load_mnist(normalize=True, one_hot_label=True)
train_size = len(x_train)
print("データ読み込み完了")
# 重み初期値補正係数
wieght_init = 0.01
#入力層サイズ
input_layer_size = 784
#中間層サイズ
hidden_layer_1_size = 40
hidden_layer_2_size = 20
#出力層サイズ
output_layer_size = 10
# 繰り返し数
iters_num = 2000
# ミニバッチサイズ
batch_size = 100
# 学習率
learning_rate = 0.1
# 描写頻度
plot_interval=10
# 初期設定
def init_network():
network = {}
network['W1'] = wieght_init * np.random.randn(input_layer_size, hidden_layer_1_size)
network['W2'] = wieght_init * np.random.randn(hidden_layer_1_size, hidden_layer_2_size)
network['W3'] = wieght_init * np.random.randn(hidden_layer_2_size, output_layer_size)
network['b1'] = np.zeros(hidden_layer_1_size)
network['b2'] = np.zeros(hidden_layer_2_size)
network['b3'] = np.zeros(output_layer_size)
return network
# 順伝播
def forward(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
hidden_f = functions.sigmoid
u1 = np.dot(x, W1) + b1
z1 = hidden_f(u1)
u2 = np.dot(z1, W2) + b2
z2 = hidden_f(u2)
u3 = np.dot(z2, W3) + b3
y = functions.softmax(u3)
return z1, z2, y
# 誤差逆伝播
def backward(x, d, z1, z2, y):
grad = {}
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
hidden_d_f = functions.d_sigmoid
last_d_f = functions.d_softmax_with_loss
# 出力層でのデルタ
delta3 = last_d_f(d, y)
# b3の勾配
grad['b3'] = np.sum(delta3, axis=0)
# W3の勾配
grad['W3'] = np.dot(z2.T, delta3)
# 2層でのデルタ
delta2 = np.dot(delta3, W3.T) * hidden_d_f(z2)
# b2の勾配
grad['b2'] = np.sum(delta2, axis=0)
# W2の勾配
grad['W2'] = np.dot(z1.T, delta2)
# 1層でのデルタ
delta1 = np.dot(delta2, W2.T) * hidden_d_f(z1)
# b1の勾配
grad['b1'] = np.sum(delta1, axis=0)
# W1の勾配
grad['W1'] = np.dot(x.T, delta1)
return grad
# パラメータの初期化
network = init_network()
accuracies_train = []
accuracies_test = []
# 正答率
def accuracy(x, d):
z1, z2, y = forward(network, x)
y = np.argmax(y, axis=1)
if d.ndim != 1 : d = np.argmax(d, axis=1)
accuracy = np.sum(y == d) / float(x.shape[0])
return accuracy
for i in range(iters_num):
# ランダムにバッチを取得
batch_mask = np.random.choice(train_size, batch_size)
# ミニバッチに対応する教師訓練画像データを取得
x_batch = x_train[batch_mask]
# ミニバッチに対応する訓練正解ラベルデータを取得する
d_batch = d_train[batch_mask]
z1, z2, y = forward(network, x_batch)
grad = backward(x_batch, d_batch, z1, z2, y)
if (i+1)%plot_interval==0:
accr_test = accuracy(x_test, d_test)
accuracies_test.append(accr_test)
accr_train = accuracy(x_batch, d_batch)
accuracies_train.append(accr_train)
print('Generation: ' + str(i+1) + '. 正答率(トレーニング) = ' + str(accr_train))
print(' : ' + str(i+1) + '. 正答率(テスト) = ' + str(accr_test))
# パラメータに勾配適用
for key in ('W1', 'W2', 'W3', 'b1', 'b2', 'b3'):
network[key] -= learning_rate * grad[key]
lists = range(0, iters_num, plot_interval)
plt.plot(lists, accuracies_train, label="training set")
plt.plot(lists, accuracies_test, label="test set")
plt.legend(loc="lower right")
plt.title("accuracy")
plt.xlabel("count")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
# グラフの表示
plt.show()正答率の出力はかなり長くなるので、最終結果のみ表示します。
Generation: 2000. 正答率(トレーニング) = 0.15
: 2000. 正答率(テスト) = 0.1135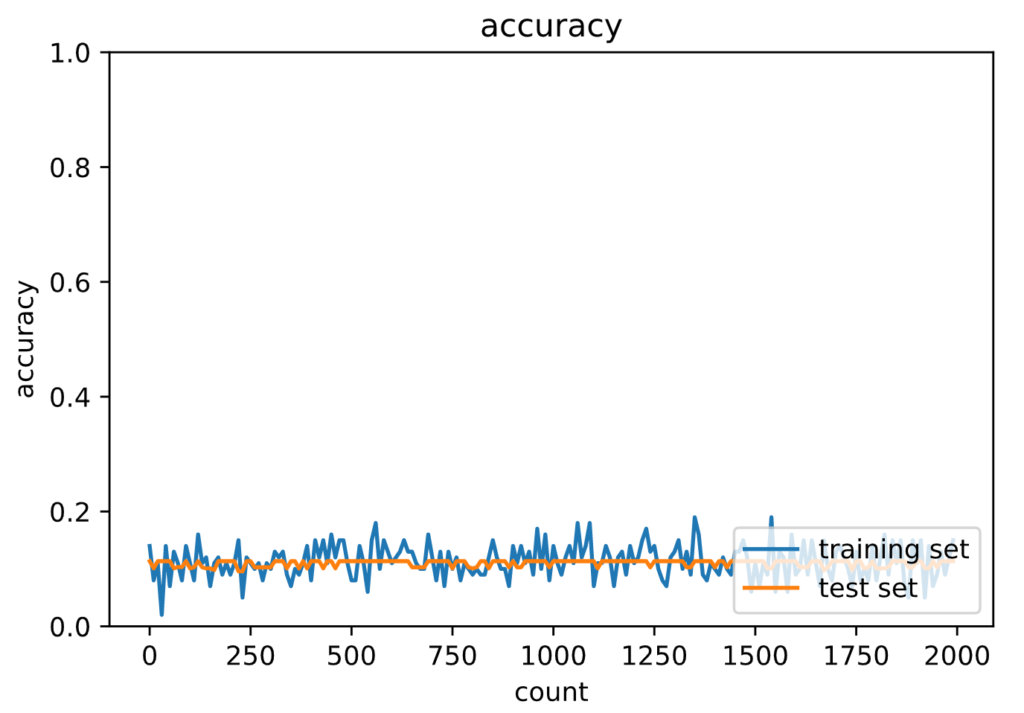
勾配が消失していることがわかります。
勾配消失の実装(ReLU関数)
続いてReLU関数で実装します。
# mnistをロード
(x_train, d_train), (x_test, d_test) = load_mnist(normalize=True, one_hot_label=True)
train_size = len(x_train)
print("データ読み込み完了")
# 重み初期値補正係数
wieght_init = 0.01
#入力層サイズ
input_layer_size = 784
#中間層サイズ
hidden_layer_1_size = 40
hidden_layer_2_size = 20
#出力層サイズ
output_layer_size = 10
# 繰り返し数
iters_num = 2000
# ミニバッチサイズ
batch_size = 100
# 学習率
learning_rate = 0.1
# 描写頻度
plot_interval=10
# 初期設定
def init_network():
network = {}
network['W1'] = wieght_init * np.random.randn(input_layer_size, hidden_layer_1_size)
network['W2'] = wieght_init * np.random.randn(hidden_layer_1_size, hidden_layer_2_size)
network['W3'] = wieght_init * np.random.randn(hidden_layer_2_size, output_layer_size)
network['b1'] = np.zeros(hidden_layer_1_size)
network['b2'] = np.zeros(hidden_layer_2_size)
network['b3'] = np.zeros(output_layer_size)
return network
# 順伝播
def forward(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
########### 変更箇所 ##############
hidden_f = functions.relu
#################################
u1 = np.dot(x, W1) + b1
z1 = hidden_f(u1)
u2 = np.dot(z1, W2) + b2
z2 = hidden_f(u2)
u3 = np.dot(z2, W3) + b3
y = functions.softmax(u3)
return z1, z2, y
# 誤差逆伝播
def backward(x, d, z1, z2, y):
grad = {}
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
########### 変更箇所 ##############
hidden_d_f = functions.d_relu
#################################
# 出力層でのデルタ
delta3 = functions.d_softmax_with_loss(d, y)
# b3の勾配
grad['b3'] = np.sum(delta3, axis=0)
# W3の勾配
grad['W3'] = np.dot(z2.T, delta3)
# 2層でのデルタ
delta2 = np.dot(delta3, W3.T) * hidden_d_f(z2)
# b2の勾配
grad['b2'] = np.sum(delta2, axis=0)
# W2の勾配
grad['W2'] = np.dot(z1.T, delta2)
# 1層でのデルタ
delta1 = np.dot(delta2, W2.T) * hidden_d_f(z1)
# b1の勾配
grad['b1'] = np.sum(delta1, axis=0)
# W1の勾配
grad['W1'] = np.dot(x.T, delta1)
return grad
# パラメータの初期化
network = init_network()
accuracies_train = []
accuracies_test = []
# 正答率
def accuracy(x, d):
z1, z2, y = forward(network, x)
y = np.argmax(y, axis=1)
if d.ndim != 1 : d = np.argmax(d, axis=1)
accuracy = np.sum(y == d) / float(x.shape[0])
return accuracy
for i in range(iters_num):
# ランダムにバッチを取得
batch_mask = np.random.choice(train_size, batch_size)
# ミニバッチに対応する教師訓練画像データを取得
x_batch = x_train[batch_mask]
# ミニバッチに対応する訓練正解ラベルデータを取得する
d_batch = d_train[batch_mask]
z1, z2, y = forward(network, x_batch)
grad = backward(x_batch, d_batch, z1, z2, y)
if (i+1)%plot_interval==0:
accr_test = accuracy(x_test, d_test)
accuracies_test.append(accr_test)
accr_train = accuracy(x_batch, d_batch)
accuracies_train.append(accr_train)
print('Generation: ' + str(i+1) + '. 正答率(トレーニング) = ' + str(accr_train))
print(' : ' + str(i+1) + '. 正答率(テスト) = ' + str(accr_test))
# パラメータに勾配適用
for key in ('W1', 'W2', 'W3', 'b1', 'b2', 'b3'):
network[key] -= learning_rate * grad[key]
lists = range(0, iters_num, plot_interval)
plt.plot(lists, accuracies_train, label="training set")
plt.plot(lists, accuracies_test, label="test set")
plt.legend(loc="lower right")
plt.title("accuracy")
plt.xlabel("count")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
# グラフの表示
plt.show()出力は次の通りです。(省略)
Generation: 2000. 正答率(トレーニング) = 0.88
: 2000. 正答率(テスト) = 0.9183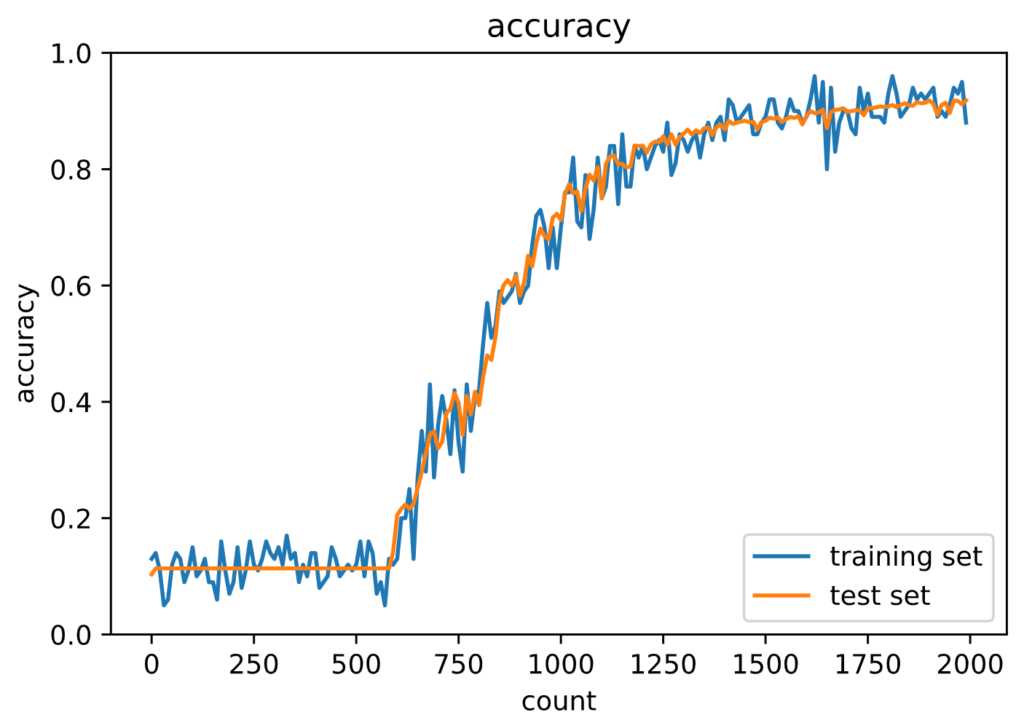
ReLU関数では勾配消失が抑制できているため、正解率が上がっていることがわかります。
初期値の変更(Xavier/シグモイド関数)
乱数を使って初期化する手法が主に使われます。
ここではXavier(ザビエル)を実装してみます。
先のコードでも、乱数をまず発生させていますが、それに対して前の層のノード数(ユニット数)の平方根で除算しています。
先ほどのコードの変更点のみ記載します。
network['W1'] = np.random.randn(input_layer_size, hidden_layer_1_size) / (np.sqrt(input_layer_size))
network['W2'] = np.random.randn(hidden_layer_1_size, hidden_layer_2_size) / (np.sqrt(hidden_layer_1_size))
network['W3'] = np.random.randn(hidden_layer_2_size, output_layer_size) / (np.sqrt(hidden_layer_2_size))# 出力
Generation: 2000. 正答率(トレーニング) = 0.76
: 2000. 正答率(テスト) = 0.7916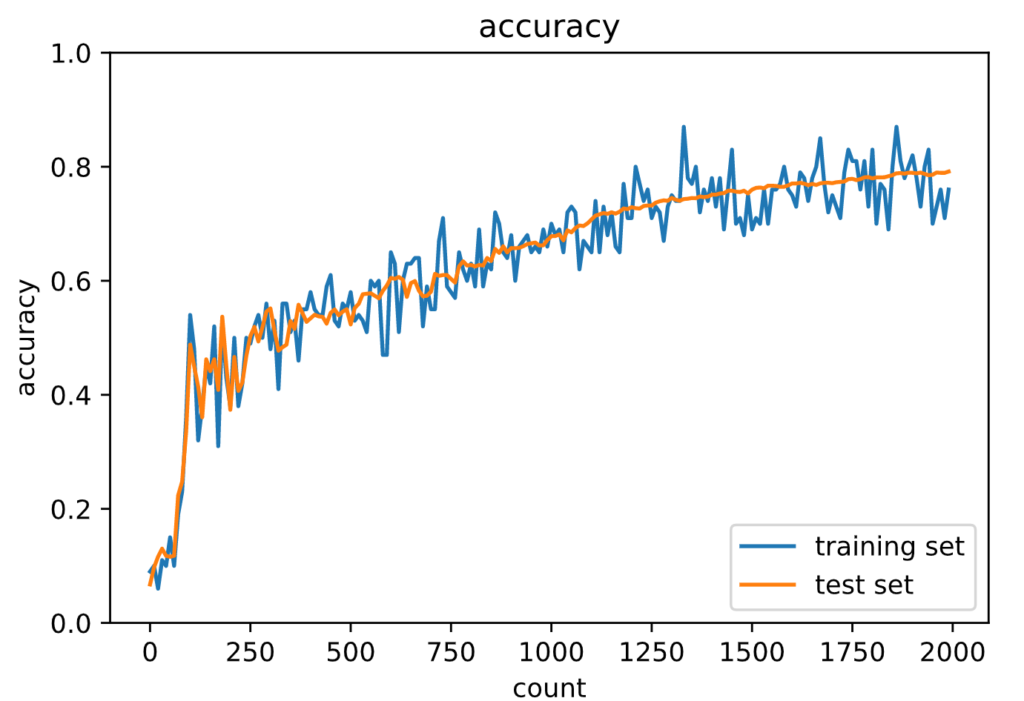
ReLU関数ほどではないですが、勾配消失は抑えられています。
初期値の調整で勾配消失を抑制できることがわかります。
初期値の変更(He/ReLU関数)
活性化関数にReLU、重みの初期値にHeを使って実装します。
Xavierに対して、\(\sqrt{2}\)で割って重みの初期化をしています。
初期値の変更点(He)を記載します。
network['W1'] = np.random.randn(input_layer_size, hidden_layer_1_size) / np.sqrt(input_layer_size) * np.sqrt(2)
network['W2'] = np.random.randn(hidden_layer_1_size, hidden_layer_2_size) / np.sqrt(hidden_layer_1_size) * np.sqrt(2)
network['W3'] = np.random.randn(hidden_layer_2_size, output_layer_size) / np.sqrt(hidden_layer_2_size) * np.sqrt(2)# 出力
Generation: 2000. 正答率(トレーニング) = 0.97
: 2000. 正答率(テスト) = 0.9567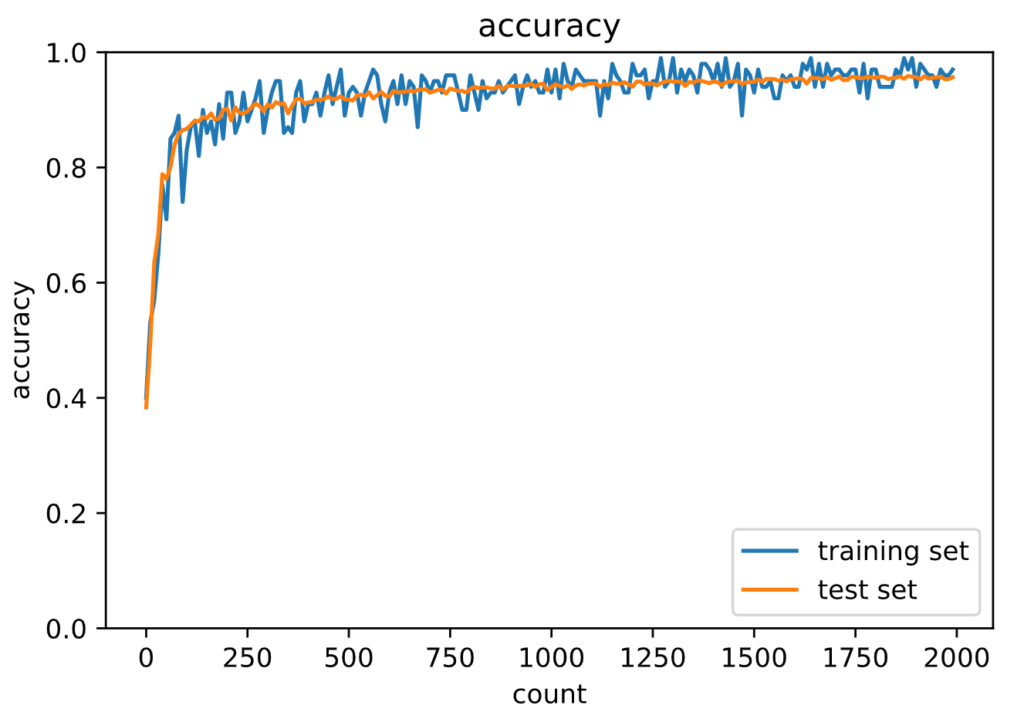
正解率が先ほどより上がっていて、学習も早いです。
学習率最適化手法
学習率の決め方
- 初期は大きく設定し、学習が進むにつれて徐々に学習率を小さくする
- パラメータごとに学習率を可変
- 学習率最適化手法を使用
学習率最適化手法は以下のようなものがあります。
- モメンタム
- AdaGrad
- RMSprop
- Adam
モメンタム
誤差をパラメータで微分した値と学習率の積を減算し、現在の重みに前回の重みを減算した値と慣性の積\(μ\)を加算します。
$$
V_{t}=\mu V_{t-1}-\epsilon\nabla E
$$
$$
w^{t+1}=w^{t}+V_{t}
$$
移動平均によって振動が抑えられているため、局所最適解に陥らず、谷間から最適解までたどり着くのが早いです。
発展型のアルゴリズムとして、勾配の向きが正しい方向を向いているかを保証したネステロフの加速勾配法(NAG)があります。
AdaGrad
誤差をパラメータで微分したもの\(\nabla E\)と再定義した学習率\(\varepsilon\frac{1}{\sqrt{h_t}+\theta}\)の積を減算します。
$$
\begin{eqnarray}
h_0&=&\theta\\
h_t&=&h_{t−1}+\left(\nabla E\right)^2\\
\mathbb{w}^{(t+1)}&=&\mathbb{w}^{(t)}-\varepsilon\frac{1}{\sqrt{h_t}+\theta} \nabla E
\end{eqnarray}
$$
勾配の緩やかな斜面に対して、最小値に近づけます。
学習率が徐々に小さくなるので、鞍点問題を引き起こす事がありました。
RMSprop
AdaGradの問題を改良したものです。
\(\alpha\quad (-<\alpha<1)\):勾配を何倍して取り込むか
$$
\begin{eqnarray}
h_t&=&\alpha h_{t−1}+(1−\alpha)\left(\nabla E\right)^2\\
\mathbb{w}^{(t+1)}&=&\mathbb{w}^{(t)}-\varepsilon\frac{1}{\sqrt{h_t}+\theta} \nabla E
\end{eqnarray}
$$
AdaGradと比較して、局所最適解にならず大域的最適解となります。
AdaGradは\(θ\)、\(ε\)をうまく調整する必要がありますが、RMSpropはハイパーパラメータの調整が必要な場合が少ない利点があります。
Adam
モメンタムとRMSpropを組み合わせた最適解アルゴリズムです。
移動平均による振動の抑制と学習率の調整をしています。
確認テスト
- モメンタム、AdaGrad、RMSpropの特徴をそれぞれ簡潔に説明せよ。
モメンタム:大局的局所解になりやすい
AdaGrad:勾配が緩やな場合でも最適解が見つけられる
RMSprop:AdaGradの改良版。局所最適解にならず大域的最適解になりやすい。モメンタムやAdaGradと比較して、ハイパーパラメータの調整が必要な場合が少ない
学習率最適化 実装演習
SGD
まずはSGDで実装します。
# 必要なライブラリのインポート
import sys, os
import sys
sys.path.append('./DNN_code_colab_lesson_1_2')
sys.path.append(os.pardir) # 親ディレクトリのファイルをインポートするための設定
import numpy as np
from collections import OrderedDict
from common import layers
from data.mnist import load_mnist
import matplotlib.pyplot as plt
from multi_layer_net import MultiLayerNet
# データの読み込み
(x_train, d_train), (x_test, d_test) = load_mnist(normalize=True, one_hot_label=True)
print("データ読み込み完了")
# batch_normalizationの設定 ================================
# use_batchnorm = True
use_batchnorm = False
# ====================================================
network = MultiLayerNet(input_size=784, hidden_size_list=[40, 20], output_size=10, activation='sigmoid', weight_init_std=0.01,
use_batchnorm=use_batchnorm)
iters_num = 1000
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.01
train_loss_list = []
accuracies_train = []
accuracies_test = []
plot_interval=10
for i in range(iters_num):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
d_batch = d_train[batch_mask]
# 勾配
grad = network.gradient(x_batch, d_batch)
for key in ('W1', 'W2', 'W3', 'b1', 'b2', 'b3'):
network.params[key] -= learning_rate * grad[key]
loss = network.loss(x_batch, d_batch)
train_loss_list.append(loss)
if (i + 1) % plot_interval == 0:
accr_test = network.accuracy(x_test, d_test)
accuracies_test.append(accr_test)
accr_train = network.accuracy(x_batch, d_batch)
accuracies_train.append(accr_train)
print('Generation: ' + str(i+1) + '. 正答率(トレーニング) = ' + str(accr_train))
print(' : ' + str(i+1) + '. 正答率(テスト) = ' + str(accr_test))
lists = range(0, iters_num, plot_interval)
plt.plot(lists, accuracies_train, label="training set")
plt.plot(lists, accuracies_test, label="test set")
plt.legend(loc="lower right")
plt.title("accuracy")
plt.xlabel("count")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
# グラフの表示
plt.show()Generation: 1000. 正答率(トレーニング) = 0.12
: 1000. 正答率(テスト) = 0.1135.png)
勾配消失が起こっていることがわかる。
モメンタム
慢性項を0.5、学習率を0.01にすると先ほどと同様勾配が消失していたので、
慢性項は0.9、学習率は0.5で実装しています。
# batch_normalizationの設定 ================================
# use_batchnorm = True
use_batchnorm = False
# ====================================================
network = MultiLayerNet(input_size=784, hidden_size_list=[40, 20], output_size=10, activation='sigmoid', weight_init_std=0.01,
use_batchnorm=use_batchnorm)
iters_num = 1000
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.5
# 慣性
momentum = 0.9
train_loss_list = []
accuracies_train = []
accuracies_test = []
plot_interval=10
for i in range(iters_num):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
d_batch = d_train[batch_mask]
# 勾配
grad = network.gradient(x_batch, d_batch)
if i == 0:
v = {}
for key in ('W1', 'W2', 'W3', 'b1', 'b2', 'b3'):
if i == 0:
v[key] = np.zeros_like(network.params[key])
v[key] = momentum * v[key] - learning_rate * grad[key]
network.params[key] += v[key]
loss = network.loss(x_batch, d_batch)
train_loss_list.append(loss)
if (i + 1) % plot_interval == 0:
accr_test = network.accuracy(x_test, d_test)
accuracies_test.append(accr_test)
accr_train = network.accuracy(x_batch, d_batch)
accuracies_train.append(accr_train)
print('Generation: ' + str(i+1) + '. 正答率(トレーニング) = ' + str(accr_train))
print(' : ' + str(i+1) + '. 正答率(テスト) = ' + str(accr_test))
lists = range(0, iters_num, plot_interval)
plt.plot(lists, accuracies_train, label="training set")
plt.plot(lists, accuracies_test, label="test set")
plt.legend(loc="lower right")
plt.title("accuracy")
plt.xlabel("count")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
# グラフの表示
plt.show()Generation: 1000. 正答率(トレーニング) = 0.97
: 1000. 正答率(テスト) = 0.9438-1024x713.png)
AdaGrad
# batch_normalizationの設定 ================================
# use_batchnorm = True
use_batchnorm = False
# ====================================================
network = MultiLayerNet(input_size=784, hidden_size_list=[40, 20], output_size=10, activation='sigmoid', weight_init_std=0.01,
use_batchnorm=use_batchnorm)
iters_num = 1000
# iters_num = 500 # 処理を短縮
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.01
train_loss_list = []
accuracies_train = []
accuracies_test = []
plot_interval=10
for i in range(iters_num):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
d_batch = d_train[batch_mask]
# 勾配
grad = network.gradient(x_batch, d_batch)
if i == 0:
h = {}
for key in ('W1', 'W2', 'W3', 'b1', 'b2', 'b3'):
# 変更
# ===========================================
if i == 0:
h[key] = np.zeros_like(network.params[key])
h[key] = momentum * h[key] - learning_rate * grad[key]
network.params[key] += h[key]
# ===========================================
loss = network.loss(x_batch, d_batch)
train_loss_list.append(loss)
if (i + 1) % plot_interval == 0:
accr_test = network.accuracy(x_test, d_test)
accuracies_test.append(accr_test)
accr_train = network.accuracy(x_batch, d_batch)
accuracies_train.append(accr_train)
print('Generation: ' + str(i+1) + '. 正答率(トレーニング) = ' + str(accr_train))
print(' : ' + str(i+1) + '. 正答率(テスト) = ' + str(accr_test))
lists = range(0, iters_num, plot_interval)
plt.plot(lists, accuracies_train, label="training set")
plt.plot(lists, accuracies_test, label="test set")
plt.legend(loc="lower right")
plt.title("accuracy")
plt.xlabel("count")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
# グラフの表示
plt.show()Generation: 1000. 正答率(トレーニング) = 0.1
: 1000. 正答率(テスト) = 0.101.png)
RMSprop
# batch_normalizationの設定 ================================
# use_batchnorm = True
use_batchnorm = False
# ====================================================
network = MultiLayerNet(input_size=784, hidden_size_list=[40, 20], output_size=10, activation='sigmoid', weight_init_std=0.01,
use_batchnorm=use_batchnorm)
iters_num = 1000
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.01
decay_rate = 0.99
train_loss_list = []
accuracies_train = []
accuracies_test = []
plot_interval=10
for i in range(iters_num):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
d_batch = d_train[batch_mask]
# 勾配
grad = network.gradient(x_batch, d_batch)
if i == 0:
h = {}
for key in ('W1', 'W2', 'W3', 'b1', 'b2', 'b3'):
if i == 0:
h[key] = np.zeros_like(network.params[key])
h[key] *= decay_rate
h[key] += (1 - decay_rate) * np.square(grad[key])
network.params[key] -= learning_rate * grad[key] / (np.sqrt(h[key]) + 1e-7)
loss = network.loss(x_batch, d_batch)
train_loss_list.append(loss)
if (i + 1) % plot_interval == 0:
accr_test = network.accuracy(x_test, d_test)
accuracies_test.append(accr_test)
accr_train = network.accuracy(x_batch, d_batch)
accuracies_train.append(accr_train)
print('Generation: ' + str(i+1) + '. 正答率(トレーニング) = ' + str(accr_train))
print(' : ' + str(i+1) + '. 正答率(テスト) = ' + str(accr_test))
lists = range(0, iters_num, plot_interval)
plt.plot(lists, accuracies_train, label="training set")
plt.plot(lists, accuracies_test, label="test set")
plt.legend(loc="lower right")
plt.title("accuracy")
plt.xlabel("count")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
# グラフの表示
plt.show()Generation: 1000. 正答率(トレーニング) = 0.99
: 1000. 正答率(テスト) = 0.944-1024x720.png)
Adam
# batch_normalizationの設定 ================================
# use_batchnorm = True
use_batchnorm = False
# ====================================================
network = MultiLayerNet(input_size=784, hidden_size_list=[40, 20], output_size=10, activation='sigmoid', weight_init_std=0.01,
use_batchnorm=use_batchnorm)
iters_num = 1000
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.01
beta1 = 0.9
beta2 = 0.999
train_loss_list = []
accuracies_train = []
accuracies_test = []
plot_interval=10
for i in range(iters_num):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
d_batch = d_train[batch_mask]
# 勾配
grad = network.gradient(x_batch, d_batch)
if i == 0:
m = {}
v = {}
learning_rate_t = learning_rate * np.sqrt(1.0 - beta2 ** (i + 1)) / (1.0 - beta1 ** (i + 1))
for key in ('W1', 'W2', 'W3', 'b1', 'b2', 'b3'):
if i == 0:
m[key] = np.zeros_like(network.params[key])
v[key] = np.zeros_like(network.params[key])
m[key] += (1 - beta1) * (grad[key] - m[key])
v[key] += (1 - beta2) * (grad[key] ** 2 - v[key])
network.params[key] -= learning_rate_t * m[key] / (np.sqrt(v[key]) + 1e-7)
if (i + 1) % plot_interval == 0:
accr_test = network.accuracy(x_test, d_test)
accuracies_test.append(accr_test)
accr_train = network.accuracy(x_batch, d_batch)
accuracies_train.append(accr_train)
loss = network.loss(x_batch, d_batch)
train_loss_list.append(loss)
print('Generation: ' + str(i+1) + '. 正答率(トレーニング) = ' + str(accr_train))
print(' : ' + str(i+1) + '. 正答率(テスト) = ' + str(accr_test))
lists = range(0, iters_num, plot_interval)
plt.plot(lists, accuracies_train, label="training set")
plt.plot(lists, accuracies_test, label="test set")
plt.legend(loc="lower right")
plt.title("accuracy")
plt.xlabel("count")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
# グラフの表示
plt.show()
Generation: 1000. 正答率(トレーニング) = 0.94
: 1000. 正答率(テスト) = 0.9435.png)


