
はじめに
今回の記事は、前回に引き続き、私が受講しているE資格 JDLA認定プログラムの「ラビットチャレンジ」のレポート記事です。
今回のテーマは機械学習のアルゴリズム(kNN・k-means)です。
コード実装を取り入れながら行っていきます。
Contents
k近傍法(kNN:k-Nearest Neighbor)
分類問題のための機械学習の教師あり学習の手法です。
最近傍のデータを\(k\)個取り、それらが最も多く属するクラスに識別します。
\(k\)の数を変えると結果も変わります。
また、\(k\)が大きいほど決定境界は滑らかになる傾向にあります。
kNN 実装演習
必要なライブラリのインポート
まず必要なライブラリをインポートします。
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from scipy import stats
from sklearn.neighbors import KNeighborsClassifier訓練データの生成
乱数を用いて分類0と分類1の変数を生成します。
def gen_data():
# 分類0の説明変数生成
x0 = np.random.normal(size=50).reshape(-1, 2) - 1
# 分類1の説明変数生成
x1 = np.random.normal(size=50).reshape(-1, 2) + 1.
# 分類0の説明変数と分類1の説明変数を1つの変数に連結。
x_train = np.concatenate([x0, x1])
# 分類0と分類1の目的変数をそれぞれ25個ずつ生成して1つに連結
y_train = np.concatenate([np.zeros(25), np.ones(25)]).astype(np.int)
return x_train, y_train
X_train, ys_train = gen_data()
plt.scatter(X_train[:, 0], X_train[:, 1], c=ys_train)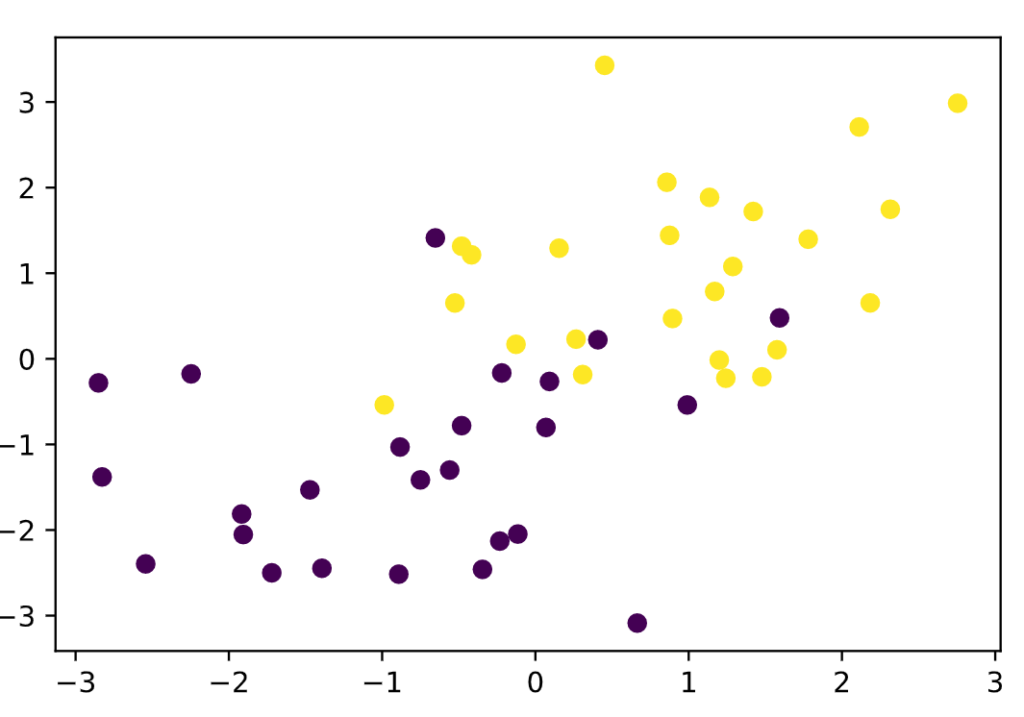
最も近いクラスに分類
xx0, xx1 = np.meshgrid(np.linspace(-5, 5, 100), np.linspace(-5, 5, 100))
xx = np.array([xx0, xx1]).reshape(2, -1).T
knc = KNeighborsClassifier(n_neighbors=n_neighbors).fit(X_train, ys_train)
plt_resut(X_train, ys_train, knc.predict(xx))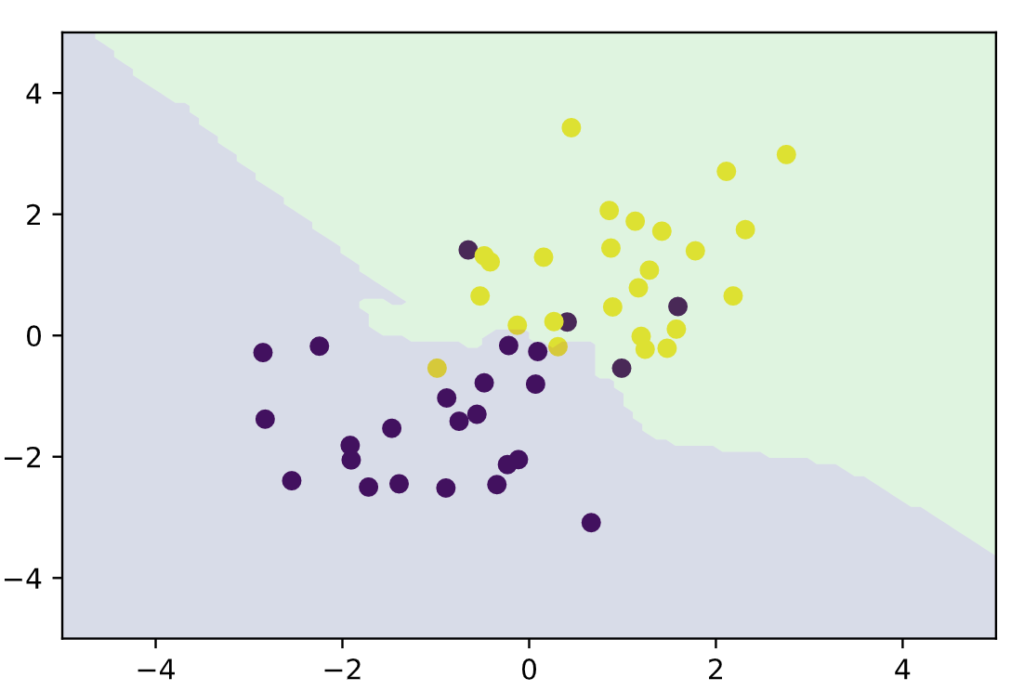
うまく分類できていることがわかります。
k-平均法(k-means)
kNNに対して、k-meansは、クラスタリングのための機械学習の教師なし学習の手法です。
クラスタリングとは、特徴の似ているもの同士をグループ化することです。
与えられたデータを\(k\)個のクラスタに分類します。
k-平均法(k-means)のアルゴリズム
- 各クラスタ中心点の初期値を設定する
- 各データ点と各クラスタ中心点の距離を計算し、各データ点が属するクラスタとして最も近いクラスタを割り当てる
- 各クラスタの平均ベクトル(中心)を計算する
- 収束するまで②〜③を繰り返す
初期値とする各クラスタの中心点が近いとうまくクラスタリングできないため、k-means++法という手法があります。
k-means++法は、最初の1つはランダムな値ではなく、データ点からランダムに選んだ点をクラスタの中心点とし、以降のクラスタ中心点は離れた位置になるように初期化されます。
これで複数の中心点が近くにならないようになるので、精度が向上します。
しかし、時間がかかる等のデメリットはあります。
k-平均法(k-means) 実装演習
# 距離の計算(ユークリッド距離の2乗)
def distance(x1, x2):
return np.sum((x1 - x2)**2, axis=1)
# クラスタ数3
n_clusters = 3
# クラスタの割り当て、クラスタ中止点更新の上限回数を100とする
iter_max = 100
# 各クラスタ中心をランダムに初期化
centers = X_train[np.random.choice(len(X_train), n_clusters, replace=False)]
for _ in range(iter_max):
prev_centers = np.copy(centers)
# 距離を保持する行列をまず0で生成
D = np.zeros((len(X_train), n_clusters))
# 各データ点に対して、各クラスタ中心との距離を計算
for i, x in enumerate(X_train):
D[i] = distance(x, centers)
# 各データ点に、最も距離が近い(argmin:最小値)クラスタを割り当てる
cluster_index = np.argmin(D, axis=1)
# 各クラスタの中心を計算
for k in range(n_clusters):
# クラスタkに属するデータのインデックス取得
index_k = cluster_index == k
# クラスタkに属するデータの平均で中心点を更新
centers[k] = np.mean(X_train[index_k], axis=0)
# 収束判定
if np.allclose(prev_centers, centers):
print(prev_centers)
break
# 可視化
def plt_result(X_train, centers, xx):
# データを可視化
plt.scatter(X_train[:, 0], X_train[:, 1], c=y_pred, cmap='spring')
# クラスタ中心点を可視化
plt.scatter(centers[:, 0], centers[:, 1], s=200, marker='X', lw=2, c='black', edgecolor="white")
# クラスタ領域の可視化
pred = np.empty(len(xx), dtype=int)
for i, x in enumerate(xx):
d = distance(x, centers)
pred[i] = np.argmin(d)
plt.contourf(xx0, xx1, pred.reshape(100, 100), alpha=0.2, cmap='spring')
# 各データがどのクラスタに属するか保持する空の配列
y_pred = np.empty(len(X_train), dtype=int)
for i, x in enumerate(X_train):
# 距離を計算
d = distance(x, centers)
# 最も距離が近い属するクラスタを取得し、設定
y_pred[i] = np.argmin(d)
# 可視化
xx0, xx1 = np.meshgrid(np.linspace(-10, 10, 100), np.linspace(-10, 10, 100))
xx = np.array([xx0, xx1]).reshape(2, -1).T
plt_result(X_train, centers, xx)
Numpyでの実装結果です。
うまくクラスタリングできていることがわかります。



