前回の記事の続き

機械学習初学者がkaggleをはじめてみた④(機械学習アルゴリズム)前回の記事の続き https://shotslog.com/%e6%a9%9f%e6%a2%b0%e5%ad%a6%e7%bf%9...
前回の記事では、ランダムフォレストとLightGBMを使って予測をしました。
今回の記事では、LightGBMのハイパーパラメータの調整をしていきます。
ハイパーパラメータチューニング
ハイパーパラメータのチューニングは手動かツールかのどちらかで行います。
まずは手動でチューニングしてみます。 前回はパラメータは下記しか指定していませんでした。
手動でチューニングしてみる
前回の記事でLightGBMを使った際は、パラメータの指定は下記の通りシンプルでした。
params = {'objective': 'binary'}指定していない他の項目はすべてデフォルトになっています。
ここでは下記の3つパラメータの値を変更します。
- max_bin を大きくする
- learning_rateを小さくする
- num_leavesを大きくする
max_binは各特徴量の最大の分割数を意味します。大きな数を指定することで過学習を抑制できます。
learning_rateは学習率です。大きなnum_iterationsを取るときに、小さな数を指定することで精度が上がります。
num_leavesは決定木における分岐の末端の最大数です。大きな数を指定することで、アルゴリズムの表現力が上がりますが、過学習が進みます。
params = {
'objective': 'binary',
'max_bin': 300,
'learning_rate': 0.05,
'num_leaves': 40
}パラメータをチューニングしたところで、予測してみます。
lgb_train = lgb.Dataset(X_train, y_train,
categorical_feature=categorical_features)
lgb_eval = lgb.Dataset(X_valid, y_valid, reference=lgb_train,
categorical_feature=categorical_features)
model = lgb.train(params, lgb_train,
valid_sets=[lgb_train, lgb_eval],
verbose_eval=10,
num_boost_round=1000,
early_stopping_rounds=10)
y_pred = model.predict(X_test, num_iteration=model.best_iteration)
# 出力
[LightGBM] [Info] Total Bins 181
[LightGBM] [Info] Number of data points in the train set: 623, number of used features: 5
[LightGBM] [Info] [binary:BoostFromScore]: pavg=0.383628 -> initscore=-0.474179
[LightGBM] [Info] Start training from score -0.474179
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
Training until validation scores don't improve for 10 rounds
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[10] training's binary_logloss: 0.503739 valid_1's binary_logloss: 0.530856
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[20] training's binary_logloss: 0.427285 valid_1's binary_logloss: 0.479331
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[30] training's binary_logloss: 0.384728 valid_1's binary_logloss: 0.456125
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[40] training's binary_logloss: 0.355475 valid_1's binary_logloss: 0.452295
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[50] training's binary_logloss: 0.332445 valid_1's binary_logloss: 0.449511
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[60] training's binary_logloss: 0.312621 valid_1's binary_logloss: 0.443413
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[70] training's binary_logloss: 0.294241 valid_1's binary_logloss: 0.440499
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[80] training's binary_logloss: 0.278628 valid_1's binary_logloss: 0.445379
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
Early stopping, best iteration is:
[72] training's binary_logloss: 0.290827 valid_1's binary_logloss: 0.440274y_pred = (y_pred > 0.5).astype(int)
y_pred[:10]
# 出力
array([0, 0, 0, 0, 1, 0, 1, 0, 1, 0])予測値が出たのでsubmitします。
sub = pd.read_csv('../input/titanic/gender_submission.csv')
sub['Survived'] = y_pred
sub.to_csv('submission_lightgbm_handtuning.csv', index=False)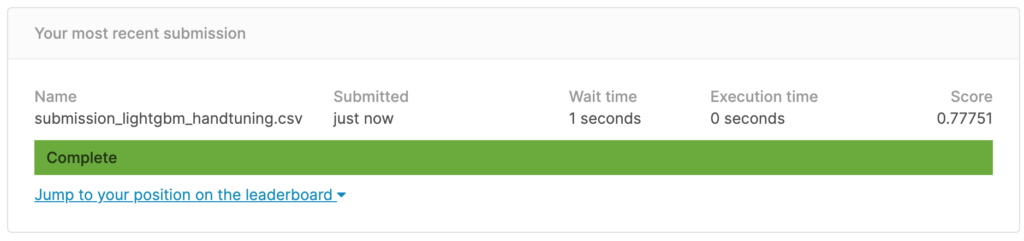
今回のscoreは0.77751。
チューニング前より改善しました。 valid_1’s binary_loglossは損失を示しますが、こちらも小さくなっています。
ツールでチューニングしてみる
ツールを使うことで、パラメータの値や組み合わせをよしなに調整してくれます。 Grid searchやBayesian Optimization、Hyperoptなど種類がありますが、ここではOptunaを使ってみます。
import optuna
from sklearn.metrics import log_loss
def objective(trial):
params = {
'objective': 'binary',
'max_bin': trial.suggest_int('max_bin', 255, 500),
'learning_rate': 0.05,
'num_leaves': trial.suggest_int('num_leaves', 32, 128),
}
lgb_train = lgb.Dataset(X_train, y_train,
categorical_feature=categorical_features)
lgb_eval = lgb.Dataset(X_valid, y_valid, reference=lgb_train,
categorical_feature=categorical_features)
model = lgb.train(params, lgb_train,
valid_sets=[lgb_train, lgb_eval],
verbose_eval=10,
num_boost_round=1000,
early_stopping_rounds=10)
y_pred_valid = model.predict(X_valid, num_iteration=model.best_iteration)
score = log_loss(y_valid, y_pred_valid)
return scorestudy = optuna.create_study(sampler=optuna.samplers.RandomSampler(seed=0))
study.optimize(objective, n_trials=40)
study.best_params
# 出力
{'max_bin': 390, 'num_leaves': 101}指定した範囲内で試行回数(40)だけ探索した結果、得られた最良のハイパーパラメータを表示しています。
subimitしてみます。
y_pred = (y_pred > 0.5).astype(int)
sub['Survived'] = y_pred
sub.to_csv('submission_lightgbm_optuna.csv', index=False)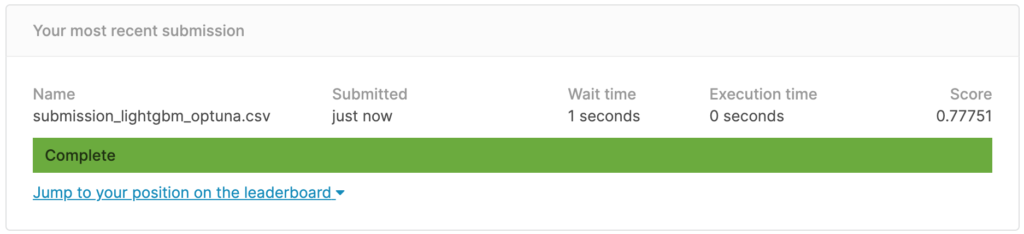
今回のscoreは0.77751。
手動のチューニングと同じ結果になりました。
まだまだ改善できそうです。
Titanicコンペは回答が用意されており、回答通りにsubmitするとscorega1になります。
なので、自分のscoreが答えを見ずに作ったものの中で何位なのか知ることができません。
このコンペで学んだことを、他のコンペに活かしていきたいと思います。