前回の記事の続き

前回の記事では、ロジスティック回帰を行いsubmitしました。
今回の記事では、ロジスティック回帰以外の機械学習アルゴリズムを試してみます。
ランダムフォレストとLightGBMにトライしてみます。
ランダムフォレストを使ってみる
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(n_estimators=100, max_depth=2, random_state=0)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)学習・予測ができたので確認してみます。
y_pred[:10]
# 出力
array([0., 0., 0., 0., 1., 0., 0., 0., 1., 0.])予測値をsubmitしてみます。
gender_submission['Survived'] = list(map(int, y_pred))
gender_submission.to_csv('submission_randomforest.csv', index=False)
gender_submission.head()
# 出力
PassengerId Survived
0 892 0
1 893 0
2 894 0
3 895 0
4 896 1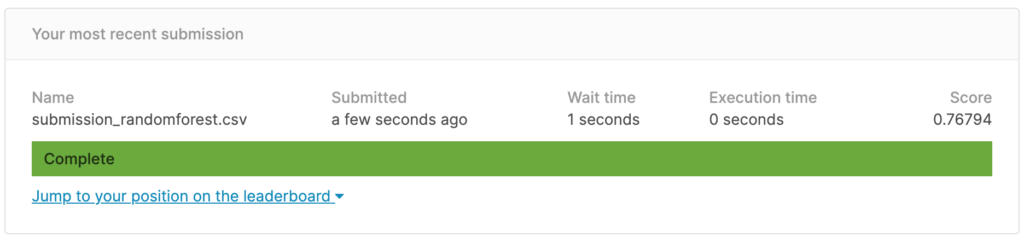
scoreは0.76794。
ロジスティック回帰を行なった時よりもscoreが上がりました。
LightGBMを使ってみる
LightGBMは決定木をもとにした機械学習アルゴリズム。
決定木は、1つの特徴量に対して1つの閾値を決め、条件分岐をしていきながら予測値を決定します。
LightGBMは勾配ブースティングと呼ばれる方法で、多くの決定木を作っていきます。
勾配ブースティングなので、ある時点で作成した決定木の予測結果を確認し、誤差の大きなデータをうまく予測できるように次の決定木を作成していきます。
最終的な予測値は、学習の過程で作成したすべての決定木での予測値を使って計算されます。
学習を重ねていくので、過学習に陥りやすいので、early stoppingを利用し、学習に利用しない検証用データセットに対する性能を見てよしなに学習を打ち切ります。
以下の事前準備が必要です。
- 学習用と検証用にデータセットを分割する
- カテゴリ変数をリスト形式で宣言する
学習用と検証用にデータセットを分割する
scikit-learnのtrain_test_splitを使ってデータを分割します。
from sklearn.model_selection import train_test_split
X_train, X_valid, y_train, y_valid = \
train_test_split(X_train, y_train, test_size=0.3,
random_state=0, stratify=y_train)LightGBMにどの変数を使うのか、リスト形式で宣言します。
categorical_features = ['Embarked', 'Pclass', 'Sex']準備が終わったので、学習・予測をしていきます。
import lightgbm as lgb
lgb_train = lgb.Dataset(X_train, y_train,
categorical_feature=categorical_features)
lgb_eval = lgb.Dataset(X_valid, y_valid, reference=lgb_train,
categorical_feature=categorical_features)
params = {'objective': 'binary'}
model = lgb.train(params, lgb_train,
valid_sets=[lgb_train, lgb_eval],
verbose_eval=10,
num_boost_round=1000,
early_stopping_rounds=10)
y_pred = model.predict(X_test, num_iteration=model.best_iteration)以下のように出力されます。
[LightGBM] [Info] Total Bins 181
[LightGBM] [Info] Number of data points in the train set: 623, number of used features: 5
[LightGBM] [Info] [binary:BoostFromScore]: pavg=0.383628 -> initscore=-0.474179
[LightGBM] [Info] Start training from score -0.474179
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
Training until validation scores don't improve for 10 rounds
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[10] training's binary_logloss: 0.426393 valid_1's binary_logloss: 0.47743
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[20] training's binary_logloss: 0.355953 valid_1's binary_logloss: 0.453224
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
Early stopping, best iteration is:
[18] training's binary_logloss: 0.365712 valid_1's binary_logloss: 0.452632early_stopping_roundsを10に設定しています。これは10回学習を重ねても検証データに対する性能が改善しなかった場合に打ち切ります。
y_pred[:10]
# 出力
array([0.06895138, 0.61735809, 0.16016727, 0.08158402, 0.46490364,
0.21711228, 0.69153324, 0.22301859, 0.69262666, 0.05348918])今回のLightGBMの設定では、0から1の連続値を出力するので、閾値を0.5より上か下かで決めます。
y_pred = (y_pred > 0.5).astype(int)
y_pred[:10]
# 出力
array([0, 1, 0, 0, 0, 0, 1, 0, 1, 0])予測値をsubmitしてみます。
gender_submission['Survived'] = y_pred
gender_submission.to_csv('submission_lightgbm.csv', index=False)
gender_submission.head()
# 出力
PassengerId Survived
0 892 0
1 893 1
2 894 0
3 895 0
4 896 0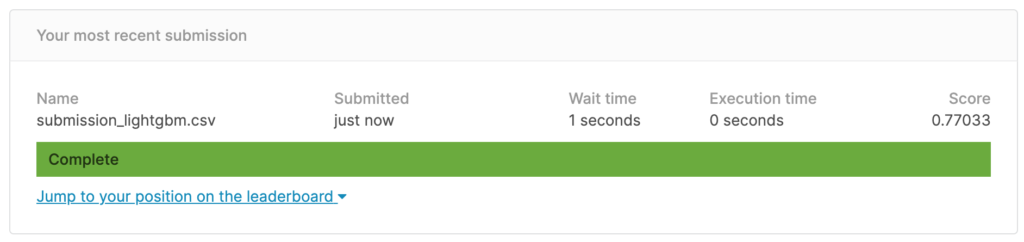
今回の記事では、ランダムフォレストとLightGBMを使って予測をしてみました。
しかし、シンプルな予測しかしていないこともあり、あまり良いscoreは出ていません。
次回はハイパーパラメータをチューニングして性能を上げていきたいと思います。